C’est un poncif des temps modernes : les datas sont partout. Elles vont révolutionner jusqu’à l’analyse de nos opinions et de nos sentiments. Mais qu’est-ce que cela signifie concrètement ?
Un nouvel antibiotique efficace contre les bactéries résistantes, développé par les ordinateurs du MIT et de Harvard, un outil imaginé par des chercheurs britanniques pour prédire les AVC et les crises cardiaques, un manga entièrement conçu et réalisé par une machine, un robot qui scanne des aliments et d’autres produits pour accélérer le passage en caisse, un système capable de repérer les erreurs dans les 52 millions d’articles de Wikipédia et de les corriger en imitant l’écriture humaine en plus de 300 langues… Une revue de presse succincte sur une dizaine de jours à peine suffit à prendre la mesure des prouesses que peut réaliser l’intelligence artificielle aujourd’hui. Car le point commun de ces innovations est qu’elles sont toutes nées d’un algorithme d’apprentissage, ou de “machine learning”, alimenté par un jeu de plusieurs milliers de données.
Menace pour les uns, opportunité historique pour les autres, l’explosion des données change déjà notre quotidien de manière sensible. Les “datas” sont partout ou presque et, combinées à une puissance de traitement informatique sans cesse décuplée, elles apportent des changements radicaux à tous les niveaux de la vie quotidienne, mais aussi à l’économie, la politique ou la recherche scientifique. Sont concernés la santé donc, mais aussi la météo, le sport, le journalisme, le droit, l’urbanisme, les transports, la banque, les assurances, le commerce… Tous ces secteurs sont impactés à plus ou moins grande échelle par les Big Data (ou le Big Data), ces “mégadonnées” qui ont atteint un tel volume qu’elles ne peuvent plus être traitées de manière humaine, ni même par des outils informatiques conventionnels.

Parmi ces données collectées par milliards en continu, beaucoup sont extraites de la multitude de traces que nous laissons chaque jour sur Internet (le Web, mais pas seulement). Et elles sont exploitées, parfois de manière industrielle, pour analyser et pourquoi pas anticiper nos pensées et désirs à venir. Ces datas offrent un champ d’études très large aux universitaires, pour des recherches globalement regroupées sous le terme d’Opinion mining (“forage d’opinions” en bon français) ou de Sentiment analysis (“analyse de sentiments”). Elles offrent aussi un terrain de jeu plus vaste encore pour un grand nombre d’entreprises allant du conseil aux forces de vente en passant par la communication, l’e-réputation, le marketing. L’analyse de nos jugements de valeur positifs ou négatifs vis-à-vis de produits, de marques, mais aussi de personnes ou de programmes politiques a désormais pris une place stratégique pour un nombre colossal de professionnels de la communication, à la recherche du bon message, à délivrer à la bonne cible.
Des mines d’or pour les marques, les entreprises, les personnalités
Les données d’opinion remontent des relations client sous toutes leurs formes bien évidemment, mais pas uniquement. Elles peuvent aussi être extraites des conversations et commentaires pléthoriques laissés sur les sites, blogs, forums, réseaux sociaux, ainsi que de formes de communication non verbales comme les emoticons, les likes sur Facebook et Twitter, les étoiles sur un film, une série, un programme, un hôtel, un restaurant ou un produit sur Amazon, etc. A cela s’ajoute un nombre gigantesque de données de consultation et de consommation qui sont trackées chez les détenteurs de cartes en tous genres, les abonnés d’un quelconque service en ligne, ou de simples internautes.
Chaque minute passée sur Internet laisse des traces qui, par extension, peuvent devenir de manière plus ou moins formelle des expressions, des opinions, des sentiments, des intentions. Parmi ces traces : les très débattus cookies qui peuvent témoigner de la consultation d’un site marchand ou d’une page produit, et donc d’une intention d’acheter, même quand la transaction ne s’est pas concrétisée. Sans rapport direct avec des données d’expression ou d’opinion, tous ces signaux sont pourtant considérés aujourd’hui eux aussi comme une matière exploitable et même comme des indices précieux par nombre d’acteurs.
Vers une exploitation de plus en plus automatisée
Avec Internet, les possibilités d’extraction des données sont nombreuses, leur usage est ensuite très hétéroclite. Ce qui n’est pas sans soulever d’importantes questions sur la protection des données personnelles, comme les scandales (Cambridge Analytica) et les débats réglementaires (RGPD, projet de recommandation “cookies” de la CNIL) nous le rappellent régulièrement. Les datas peuvent servir à alimenter des outils de veille pour le contrôle qualité des produits. Elles sont aussi utilisées dans des dispositifs d’alerte contre les atteintes à la réputation d’une marque ou d’une personnalité, à l’heure où les “bad-buzz”, “shitstorm” et autre “trolling” peuvent détruire une image en quelques heures sur les réseaux sociaux. Les commentaires de blogs ou les étoiles de sites spécialisés sont utilisés pour prédire le succès commercial d’un film et donc orienter la stratégie d’exploitation en salle. Le crawl de données financières permet d’anticiper l’évolution d’actions cotées en Bourse… Mais toutes ces données sont le plus souvent exploitées à des fins commerciales, pour cibler un prospect et le convertir en client d’abord, puis pour éviter de le perdre ensuite (“attrition” ou “churn”).
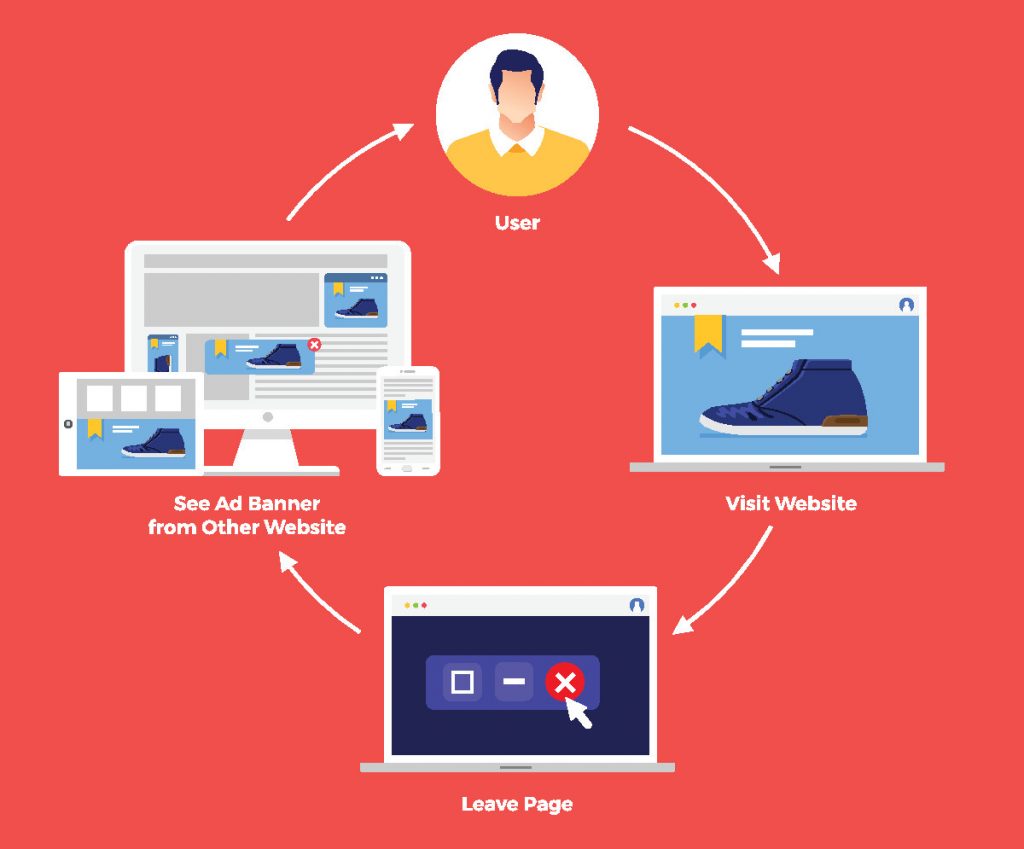
La masse des données étant quasi infinie, une tendance à automatiser au maximum les procédures de collecte, d’archivage, de constitution des bases de données, et même d’exploitation opérationnelle de ces dernières, s’est manifestée. L’usage le plus visible pour les utilisateurs du Web étant sans doute la publicité programmatique et son corollaire, le retargeting. N’avez-vous jamais vécu cette intense expérience numérique consistant à retrouver systématiquement dans des publicités ciblées la paire de chaussures que vous veniez d’admirer sur un site marchand, sans jamais avoir l’intention de l’acheter ? Cette tendance à l’automatisation nécessite l’usage de plus en plus répandu et affiné d’algorithmes, et donc l’utilisation de l’intelligence artificielle.
Du Big Data à l’intelligence artificielle
Traiter des millions ou même des milliards de données, souvent en temps réel, et parfois avec une action immédiate à la clé, a très vite appelé de nouvelles compétences et invité de nouveaux acteurs dans les univers du marketing, de la communication ou de la publicité. Les chargés d’étude ont laissé place aux statisticiens, puis aux mathématiciens jusqu’aux “data scientists”. Leur mission : développer des outils d’intelligence artificielle pour traiter et analyser ces flux de données de manière optimisée et les passer au crible d’une analyse prédictive.
La définition la plus basique d’une intelligence artificielle la résume à un processus visant à simuler l’intelligence humaine avec des machines. Mais on peut aussi l’envisager comme une série d’algorithmes permettant de réaliser des opérations complexes en vue d’un résultat. Si parfois on évoque l’intelligence artificielle comme un ensemble, celui de toutes les théories et outils du genre à travers le monde, il est sans doute plus pertinent de parler d’une multitude d’intelligence artificielles fonctionnant sur des modèles parfois radicalement différents selon les laboratoires, les ingénieurs, les statisticiens, les mathématiciens ou informaticiens à l’œuvre.
Le “machine learning” est à la fois l’une des grandes catégories d’intelligence artificielle et sa traduction la plus évidente. Cette fois, les algorithmes vont “apprendre” des scénarios en fonction d’une masse de données, permettant à la machine d’optimiser ses résultats et ses performances dans une relative autonomie. Moyennant l’agrégation de données massives, la machine sera en mesure “d’apprendre par elle-même”, le travail du programmateur consistant alors à fixer et à contrôler l’objectif de cet apprentissage et à fournir les jeux de données idoines. Reste que pour le commun des mortels, et en particulier pour les clients des solutions d’intelligence artificielle ou de machine learning, faire appel à ces technologies revient bien souvent à accorder sa confiance à une “boîte noire”, comme l’a justement souligné le mathématicien et député Cédric Villani dans un rapport en mars dernier, intitulé “Donner un sens à l’intelligence artificielle”. Une “boîte noire” dans laquelle il n’est pas inutile de jeter un oeil de temps en temps.